腾讯 Marvis 本地模式深度测评:隐私保护,值不值得牺牲一点速度?
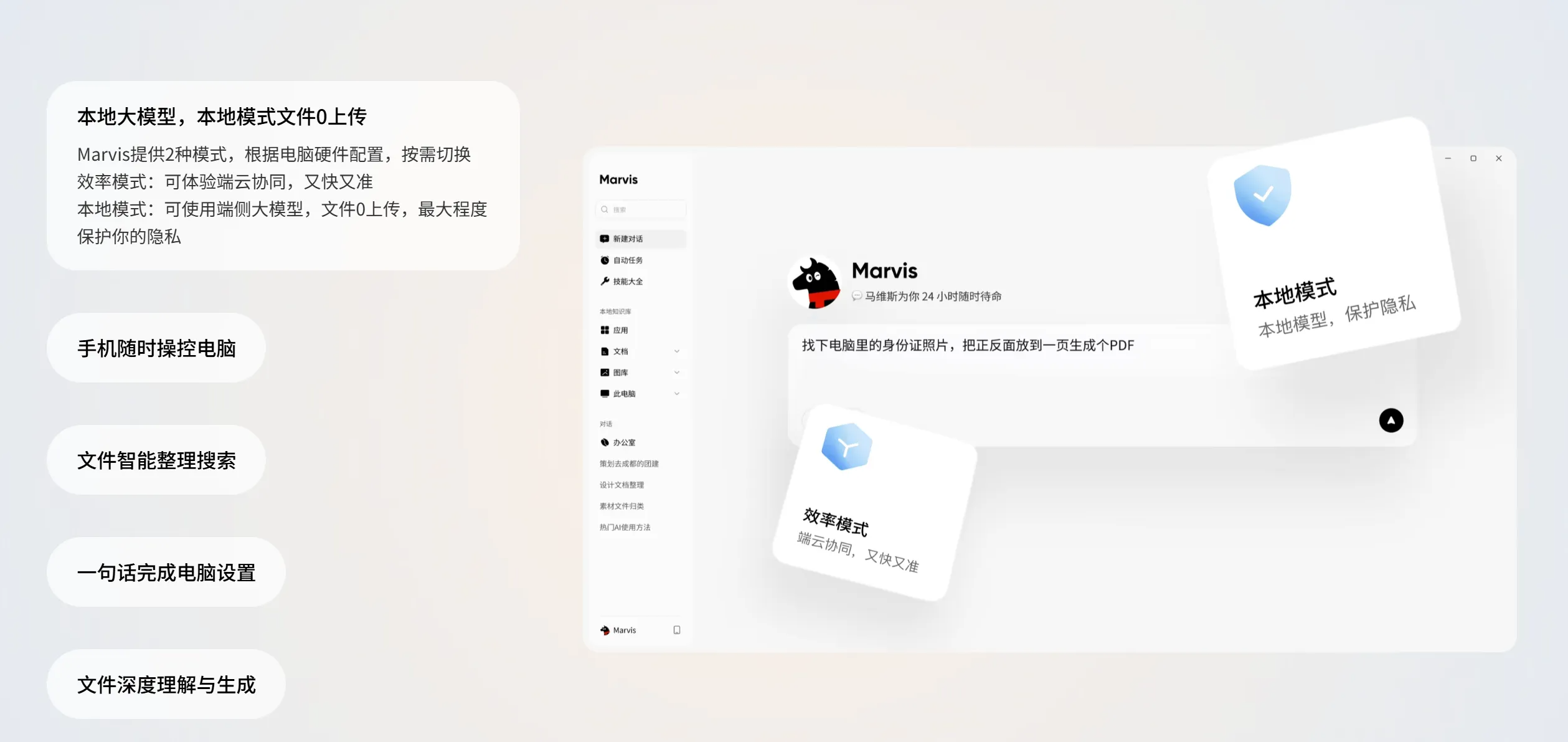
很多人第一次看到 Marvis,最容易被“手机控电脑”“系统级 AI 助手”“直接操作本地文件”这些点吸引住。
但如果你真准备把它接进日常工作流,真正绕不开的问题其实是另一个:
本地模式,到底值不值得开?
我这次专门翻了几篇公开实测稿,重点不再看“它能干什么”,而是看:
- 本地模式和效率模式到底差在哪
- 速度差多少
- 隐私边界是不是够硬
- 什么场景该上本地模式
- 什么场景反而别逞强
看完以后,我的判断很明确:
如果你处理的是合同、财务、人事、敏感项目资料这类不能轻易上云的内容,Marvis 本地模式非常值得;但如果你电脑配置一般、任务又偏长文复杂推理,那你需要接受一个现实:本地模式更安全,但通常也更慢。
先说结论
- 截至 2026 年 6 月 29 日,从公开实测口径看,
Marvis的两种底层运行方式可以粗暴理解成:- 效率模式:端云协同,更快、更强,适合大多数普通任务
- 本地模式:文件和数据尽量不离机,更适合高敏感任务
- 如果你最在意:
- 合同
- 财务表
- 人事资料
- 本地文件隐私
那
Marvis本地模式是它最有产品辨识度的地方之一。
- 如果你最在意:
- 复杂长文推理
- 超大文件处理
- 老旧电脑配置下的流畅度 那本地模式未必是默认最优解。
为什么本地模式是个真正的产品分水岭
很多 AI 工具其实也会讲“隐私”“安全”“企业级”,但说到底,很多产品的默认逻辑还是:
- 数据上传云端
- 模型在云端推理
- 本地只是一个输入窗口
Marvis 不一样的地方,在于它真的把“本地模式”做成了一个产品层面的选择,而不是一行宣传语。
公开实测稿里提到的核心差别很直接:
- 效率模式
- 端云协同
- 任务理解和规划可以借助云端模型
- 响应快,逻辑更强
- 本地模式
- 使用端侧模型
- 文件处理、索引构建等数据尽量不出电脑
- 更适合高度敏感数据
这也是为什么我会说,它真正的分水岭不是“会不会聊天”,而是:
你到底把它当成云助手,还是本地工作台。
对比 1:本地模式最值钱的,不是技术炫技,而是文件 0 上传
公开图里有一句非常抓人的口径:
- 本地大模型,本地模式文件 0 上传
这句话为什么重要?因为很多办公场景里,真正让人不敢用 AI 的不是“效果不行”,而是:
- 文件能不能留在本地
- 财务数据会不会上云
- 合同内容会不会进入第三方系统
- 项目资料能不能只在自己的电脑里跑
对于下面这些东西,本地模式的意义就不是“快不快”,而是:
- 财务报表
- 法务合同
- 招投标文件
- 人事档案
- 客户名单
- 商业策略文件
只要你的工作碰这些内容,你就会明白:
本地模式的价值,首先不是提升体验,而是给你一个敢用的理由。
对比 2:公开实测已经把代价讲得很清楚了,本地模式通常更慢
我不想把本地模式写成“又安全又快又全能”,因为公开实测稿里其实已经把现实讲明白了。
几篇文章里都提到了类似结论:
- 本地模式响应会比云端慢一些
- 复杂推理时体感差距会更明显
- 大文件、长文档、重分析任务更吃硬件
特别是公开对比稿《Marvis vs ChatGPT/Claude:企业办公AI落地真实对比》里,已经把这个问题点得很具体:
- 本地模式处理大文件时,对电脑硬件要求明显更高
- 如果是
i5 + 8GB这种级别,体验可能会掉得比较厉害 - 更推荐
i7 + 16GB这类配置
这很合理。因为本地模式的本质,就是:
把一部分原本放在云上的算力压力,重新压回你的电脑。
所以它不是“无成本的隐私”,而是:
用本地硬件和一点等待时间,换取更强的数据边界。
对比 3:并不是所有场景都该开本地模式
这是我觉得很多人最容易搞错的一点。
很多人一听“本地模式更安全”,就会下意识觉得:
- 那我以后全开本地模式不就好了?
但从公开实测口径看,这种理解很容易走偏。
因为 Marvis 的产品设计本身就在暗示一个更现实的用法:
- 日常普通任务
- 走效率模式
- 高敏感文件
- 切本地模式
这其实就是一种很实用的分层策略。
更适合开本地模式的任务
- 合同审查
- 财务分析
- 人事文件处理
- 本地文件检索
- 敏感项目资料归档
更适合继续用效率模式的任务
- 普通内容写作
- 通用计划书
- 长篇复杂推理
- 非敏感文件的总结整理
- 对速度要求特别高的任务
如果一句话总结,就是:
本地模式不是默认全开,而是应该在真正需要隐私边界时开。
对比 4:手机控电脑和本地模式组合在一起,才是它更像“企业助理”的地方
我觉得 Marvis 最不像普通聊天工具的地方,是它把本地模式、文件处理和跨端协同绑在了一起。
在公开实测里,有几个很典型的动作:
- 手机看到电脑桌面
- 远程找文件
- 压缩文件
- 发邮件
- 通过微信发出去
如果这些动作只发生在云端,其实很多企业不会放心。 但如果文件和执行主要留在本地,本地模式的价值就被放大了。
因为很多企业真正想要的不是:
- AI 更会说话
而是:
- AI 能不能接住本地电脑上的事
- 同时又不要把重要文件轻易送出本机
也就是说,本地模式单看只是“隐私功能”,但和手机控电脑、文件搜索、系统级操作结合起来看,它更像:
企业本地工作流的安全阀。
对比 5:安全边界不只是“本地不上传”,还包括关键动作的二次确认
另一个我觉得很重要的点,是公开实测稿里提到:
- 涉及系统关键设置修改
- 比如删除系统文件、修改注册表
- 会弹窗要求用户二次确认
这说明它的安全边界并不是只有“文件不上传”这一层,还有:
- 关键动作必须确认
- 系统级修改不放任自由执行
这对本地模式其实非常关键。因为越接近本机、越接近真实文件和系统,越不能只强调“方便”,还得强调:
可控。
否则本地模式就只是“更有权限”,而不是“更适合企业”。
从公开实测里,我看到的真实取舍是什么
把几篇公开稿拼起来看,Marvis 本地模式的真实取舍其实很清楚:
- 你获得的是:
- 更强的隐私边界
- 文件 0 上传
- 更适合敏感办公资料
- 更贴近本地文件和系统任务
- 你付出的通常是:
- 更慢的响应
- 更高的硬件要求
- 在复杂长文推理上的劣势
这不是缺点,而是非常典型的工程权衡。
所以我更愿意把它理解成:
不是“本地模式是不是最好”,而是“本地模式是不是值得在关键时刻打开”。
它现在最适合哪些人先试
适合马上试的人
- 对数据隐私极度敏感的企业团队
- 经常处理合同、财务、人事文件的人
- 已经把很多资料放在本地电脑或共享目录里的人
- 想让 AI 真接近本地文件、又不想默认上云的团队
- 本地电脑配置还不错的知识工作者
可以先观望的人
- 电脑配置偏弱、又想长时间重度本地推理的人
- 主要需求是长文写作和超长上下文的人
- 任务大多不敏感、只追求最快速度的人
- 没有本地文件和系统操作诉求、只是想聊聊天的人
如果你想自己测,我建议这样测
- 不要只测“聊天快不快”,直接拿敏感办公任务测。
- 最适合拿来比的切口通常是:
- 合同审查
- 财务表分析
- 本地文件检索
- Excel / Word 输出
- 手机远程处理本地文件
- 不只看回答质量,重点看:
- 文件是否真能不上传
- 本地模式速度是否可接受
- 硬件能不能扛住
- 关键动作是否有确认边界
- 如果你们本来就在做企业 AI 试点,也可以顺手比较:
- 哪些任务坚持本地模式
- 哪些任务继续走效率模式
- 哪些任务干脆交给
Claude或ChatGPT
如果你现在更关心的是:怎样把腾讯系、GLM、Kimi、DeepSeek、StepFun 等模型统一接进自己的 Agent 工作流,可以先看:
我的最终判断
如果一句话总结我对 Marvis 本地模式 的看法,那就是:
它最值得重视的,不是“本地模式也能跑大模型”这件事本身,而是它给了企业办公一个更现实的选项:在真正敏感的任务里,用一点速度和硬件成本,换更清晰的隐私边界。
这比单纯比较谁更快更聪明更重要。因为很多企业真正缺的,从来不是一个更能说的 AI,而是:
一个既能接近本地文件和系统任务、又不必默认把数据交给云端的工作入口。
如果你的核心目标是安全边界和本地执行,Marvis 本地模式很值得认真试。
如果你的核心目标只是最快的通用生成,它就未必是默认最优解。