Seed2.1 测评:字节跳动这代 Agent / Coding 模型,值不值得现在就试?
Seed2.1 确实已经正式发布了。更准确地说,字节跳动 Seed 在 2026 年 6 月 23 日 发布的是一套面向真实生产力场景的模型系列,包含 Seed2.1 Pro 和 Seed2.1 Turbo 两个版本;官方同时明确写到,这一系列已经在 豆包产品、TRAE 和 火山引擎 API 上线。
我把字节跳动 Seed 的官方项目页、发布博客,以及项目页里列出的核心评测结果过了一遍。我的结论先放前面:如果你主要看重 Agent 执行、代码工程、多模态理解和跨工具任务交付,Seed2.1 很值得进入测试名单;但如果你只是想找一个“普通聊天更顺手”的通用模型,那这次升级最亮眼的地方并不在闲聊,而在生产力工作流。
TL;DR
Seed2.1于 2026 年 6 月 23 日 正式发布。- 这一代不是只强调聊天体验,而是更明确地冲着 Agent、Coding、Computer Use、多模态生产力 去的。
- 官方给出的模型形态是 Pro / Turbo 两个版本。
- 官方博客明确写到:Seed2.1 系列已在豆包、TRAE 和火山引擎 API 上线。
- 在公开和官方自建评测里,Seed2.1 重点强化的是:通用 Agent 交付稳定性、代码工程端到端能力、复杂视觉/视频理解、长上下文任务推进。
- 如果你真正要测的,是“让模型围绕目标持续干活”,而不是“单轮答题漂不漂亮”,那 Seed2.1 这次很值得认真看。
Seed2.1 到底是什么
从官方页面和发布博客看,Seed2.1 的定位非常明确:它不是一个只追求单项 benchmark 漂亮分数的通用对话模型,而是一套更偏向 真实生产力场景 的智能体模型。
官方自己总结了三条主线:
- 更可靠的通用 Agent 能力
- 更稳定的代码工程交付能力
- 更强的多模态、知识、推理和视频理解能力
这套说法翻译成大白话,就是它要解决的不是“会不会回答”,而是:
- 能不能围绕任务目标持续推进
- 能不能跨文件、跨工具、跨环境交付结果
- 能不能在复杂视觉材料、长文档、长视频里少误读
我觉得最值得关注的 4 个点
1. 它更像“生产力 Agent 模型”,不是普通聊天模型的微调版
官方反复强调的,不是单轮输出更像人,而是 在真实工作流中持续推进任务。
Seed 团队给出的例子包括:
- 项目规划
- 文件处理
- 工具调用
- 教案 PPT 生成
- 复杂表格分析
- 行业报告生成
这些任务的共同点,不是“回答一个问题”,而是要把多个步骤串起来,并最后交付一个可用结果。
如果你现在做的是 AI 办公助手、研究助理、自动化工作流、Agent 产品,或者想让模型在浏览器、文档、代码仓库、外部工具之间来回切换,这个方向就很对口。
2. 它这次对 Coding 的强化不是写几段代码,而是端到端交付
字节官方博客里,对 Coding 的表述很直接:Seed2.1 提升的是 端到端代码工程交付能力,包括:
- 需求理解
- 功能实现
- bug 修复
- 运行环境搭建
- 结果验证
这跟很多“代码模型发布”喜欢展示的单文件补全不是一回事。它要解决的是更像真实企业开发的问题:看懂整个仓库、做多文件改动、最后把事情收口。
如果你平时要评估模型是否适合 Coding Agent,最该看的不是“会不会写一个排序函数”,而是:
- 能不能理解仓库结构
- 能不能在多文件修改后保持可维护性
- 能不能把验证这一步也做掉
官方博客里提到,Seed2.1 Pro 在 NL2Repo-Bench 上表现良好,这个基准本来就是为了考察自然语言需求到仓库级代码改动的能力,跟真实工程更接近。
3. 它在 Agent / CUA 方向比很多“只会说不会做”的模型更有意思
Seed2.1 另一个明显强化方向,是 跨工具、跨环境、跨 GUI 与非 GUI 操作空间 的任务执行。
官方博客提到几个很有代表性的点:
- 在 MobileWorld 上取得最高分
- 在 OSWorld 上保持竞争力
- 通过强化学习,把任务完成所需的平均步数减少 16%
- 在 CreativeWork 上表现突出
这说明它不是只会“建议你下一步做什么”,而是在往真正的 Computer-Use Agent 方向推进。
如果你的产品里有下面这些需求,Seed2.1 会比“普通问答模型”更值得试:
- 手机 GUI 自动化
- 浏览器 / 文档 / 设计工具混合任务
- 在 Notion、Canva、Figma 一类环境里做复杂交付
- 需要模型自己决定是该点按钮还是该调工具
4. 多模态不是点缀,而是直接服务执行链路
官方项目页和博客都强调,Seed2.1 进一步打通了 感知、理解、执行 这条链路。
给的场景例子包括:
- 根据户型图、设计稿和视频直接生成可交互页面
- 基于长视频完成理解、剪辑和解说成片
- 理解多张真实照片并绘制平面户型图
这意味着它的多模态能力不是单纯“看图说话”,而是更偏:
- 文档 / 图表 / PDF 理解
- 图像到结构化结果
- 视频到任务执行
- 视觉信息辅助代码生成和内容生成
对于要做“截图转前端”“图表分析”“视频理解”“视觉 Agent”的团队,这个方向比单纯多一两个视觉 benchmark 分数更有意义。
官方数据里,哪些信号最值得看
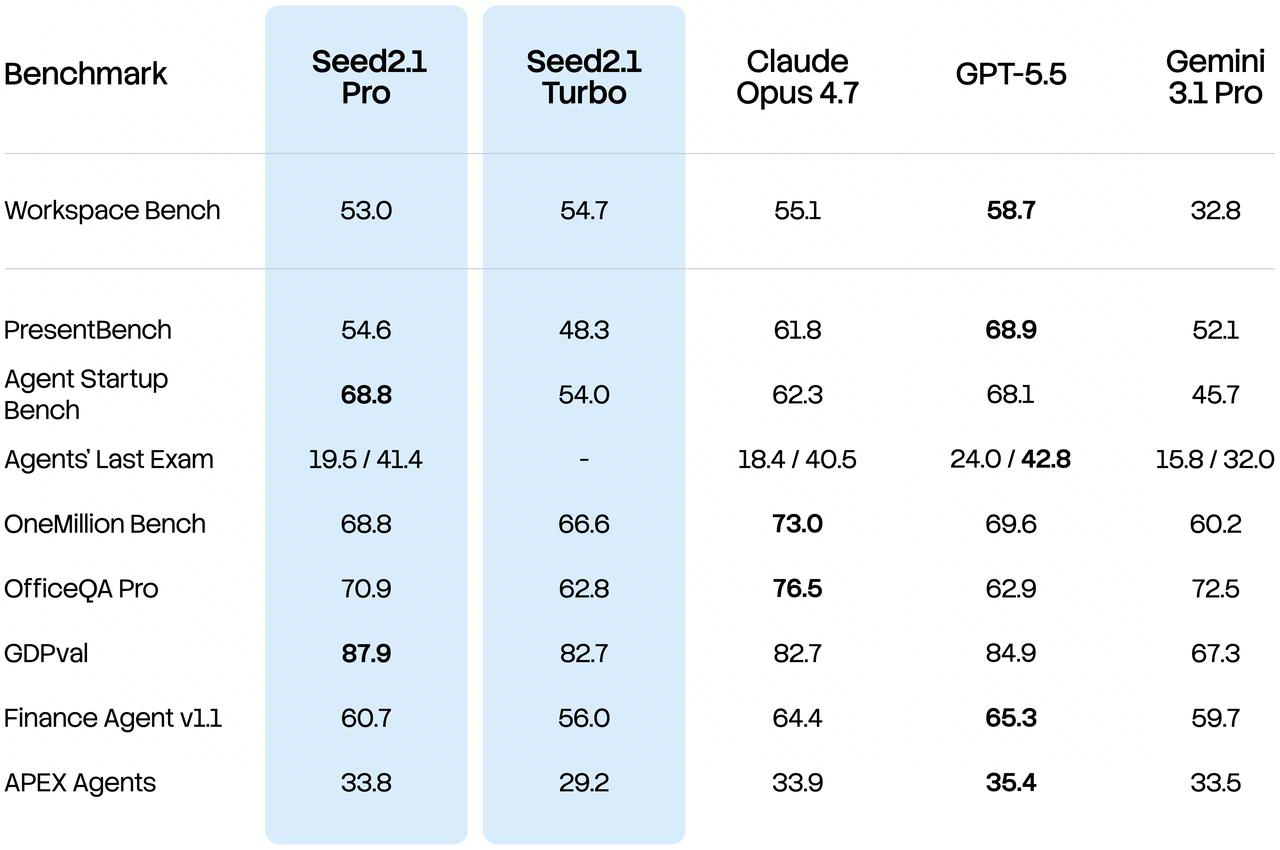
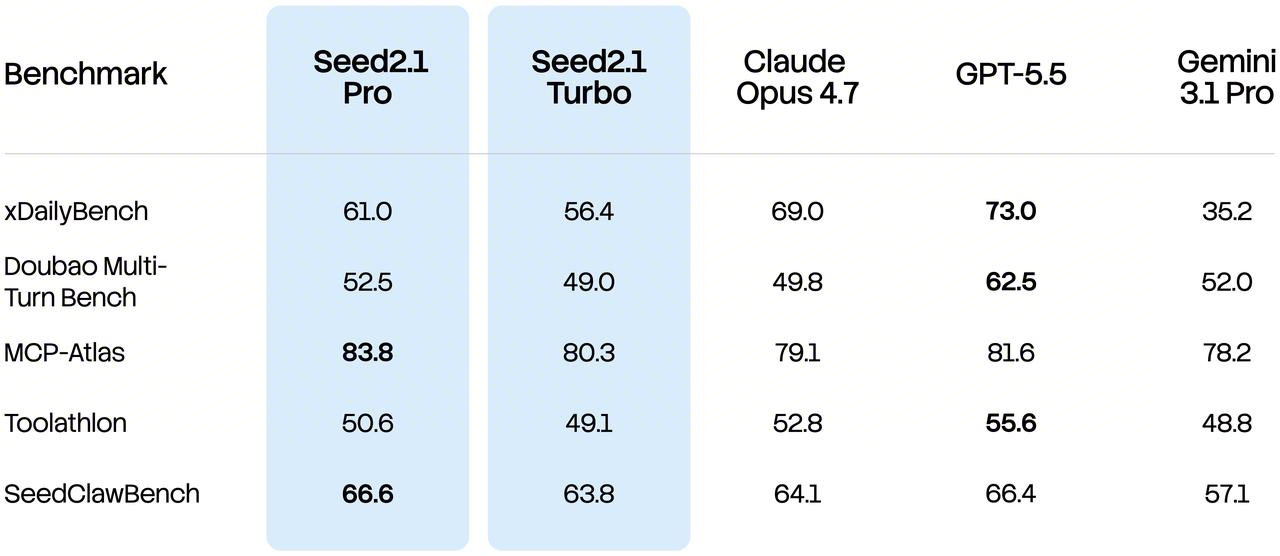
官方页面和博客里提到的评测很多,但我觉得最值得普通开发团队优先关注的是下面几类:
通用 Agent / 高经济价值任务
- GDPVal:官方博客明确写到,
Seed2.1 Pro在这个基准上拿到最高分。 - Workspace Bench
- Agent Startup Bench
- Agents' Last Exam (ALE):官方把它描述为第一梯队水平。
这组指标更接近“模型能不能在真实工作中帮你完成事”。
Coding / 软件工程
- ProgramBench
- NL2Repo-Bench
- Code Arena: Frontend:官方博客写到,
Seed2.1 Preview在该榜单以 1539 分排第 8,并在 7 个前端子类别中的 5 个进入前 10。
另外,官方博客还提到一个非常抓人的结果:在众测开发者基于真实代码仓库提交工程任务的匿名对比中,Seed2.1 Pro 相比 Claude Opus 4.6 获得 59.1% 胜率。 这个数字当然仍然属于官方口径,但它比单纯静态答题 benchmark 更接近真实工程使用体验。
多模态 / 长上下文 / 视频理解
- CharXiv-RQ
- MeasureBench
- ERQA
- MMLongBench-128K
- VideoMME
- TVBench
- TOMATO
从官方描述看,Seed2.1 这次很明确地想证明:它不是只有文字强,而是想在 复杂视觉材料、空间理解、长文档、多页材料、长视频 这些对 Agent 更关键的场景里一起提升。
但我不建议把它吹成“万能大一统模型”
Reddit 风格说一句:Seed2.1 看起来很猛,但别一看到 Agent + Coding + 多模态就自动脑补成“全场景无脑替代一切”。
我现在最保留的三点是:
1. 这些亮点大多来自官方页面和官方博客
这不代表它不强,但代表你在引用时要注意语境。像:
- “最高分”
- “第一梯队”
- “59.1% 胜率”
- “SOTA”
这些都应该优先视为 官方披露结果,不是已经被全行业独立复现的结论。
2. 它更强的是任务交付,不一定是所有轻任务都更省
如果你的任务只是:
- 短问答
- 简单写作
- 单步工具调用
- 很轻的代码补全
那你真正该比的,可能不是“谁功能更全”,而是“谁便宜、谁快、谁稳定”。
也就是说,Seed2.1 的价值更像高价值任务里的完成度,而不是所有场景都一定性价比最高。
3. 官方公开页没有把价格讲得特别完整
截至 2026 年 6 月 25 日,我在字节跳动 Seed 官方项目页和发布博客里能明确确认的是:
- 系列模型已经上线
- API 已在火山引擎上线
- 对应模型名为 Doubao-Seed-2.1-Pro / Doubao-Seed-2.1-Turbo
但官方项目主页本身没有像一些商业 API 页面那样,把价格、倍率、缓存命中计费等采购细节完整摊平。 所以如果你关心的是“上线以后每 1M token 到底多少钱、适不适合长期跑业务”,最后还是得回到实际控制台和采购侧口径。
谁适合现在就试 Seed2.1
适合马上试的人
- 在做 Agent 产品、AI 办公、研究助理、自动化工作流的团队
- 需要模型在文档、浏览器、代码仓库、外部工具之间切换的场景
- 在找更强的中文 / 多模态 / Coding 综合能力路线的人
- 想重点评估 Computer Use、GUI Agent、前端生成、长视频理解的团队
可以先观望的人
- 只做普通聊天和轻问答
- 任务很短,不涉及长链路执行
- 主要比较的是最低成本,而不是最强交付能力
- 还没有真实 Agent 任务,只是偶尔让模型写几段代码
如果你想接进业务,我建议这样测
- 先拿 3 到 5 个真实工作流任务做 A/B 测试。
- 不只测问答,重点测“是否真的把事情做完”。
- 记录四件事:完成率、返工次数、总耗时、总 token。
- 把 GUI / 工具调用 / 多模态输入一起放进测试,而不是只测纯文本。
- 对官方结果保持乐观,但上线决策仍然以自己的任务集为准。
如果你现在更关心的是:如何统一比较字节系模型与 Kimi、GLM、DeepSeek、StepFun 等国产模型的接入成本和兼容方式,可以先看:
需要说明的是,当前站内价格页实时清单已同步的是豆包 doubao-seed-2.0-code / pro 等已接入型号;Seed2.1 的接入状态以控制台和价格页实时展示为准。
我的最终结论
如果一句话总结我对 Seed2.1 测评 的看法,那就是:
它不是那种“单轮聊天更丝滑”的小修小补,而是字节跳动在 Agent、Coding、GUI 与多模态生产力场景上的一次更明确收口。
它最值得重视的地方,不是某一个单项榜单,而是这几个方向一起被强化了:
- 通用 Agent 任务推进
- 代码工程端到端交付
- 跨工具、跨环境执行
- 复杂视觉与长视频理解
如果你的核心诉求是 真实工作流交付,Seed2.1 值得认真进测试池。 如果你的核心诉求只是 最便宜的轻量调用,那它是不是最优选,还得看你自己的采购成本和任务类型。
FAQ
Seed2.1 是什么时候发布的?
根据字节跳动 Seed 官方发布博客,Seed2.1 于 2026 年 6 月 23 日 正式发布。
Seed2.1 有哪些版本?
官方项目页明确给出两个版本:Seed2.1 Pro 和 Seed2.1 Turbo。
Seed2.1 现在哪里可以体验?
根据官方博客,截至 2026 年 6 月 23 日,Seed2.1 已在:
- 豆包产品
- TRAE
- 火山引擎 API
上线。官方给出的模型名包括 Doubao-Seed-2.1-Pro 和 Doubao-Seed-2.1-Turbo。
Seed2.1 更适合什么任务?
从官方口径看,它更适合:
- 通用 Agent
- 代码工程
- Computer Use / GUI 任务
- 多模态理解
- 长视频理解
Seed2.1 值不值得现在就试?
如果你在做的是 Agent、Coding、多模态生产力工作流,答案是值得。 如果你要的是最简单、最便宜的轻任务调用,那它是否划算,还是要回到你自己的任务集和采购成本。