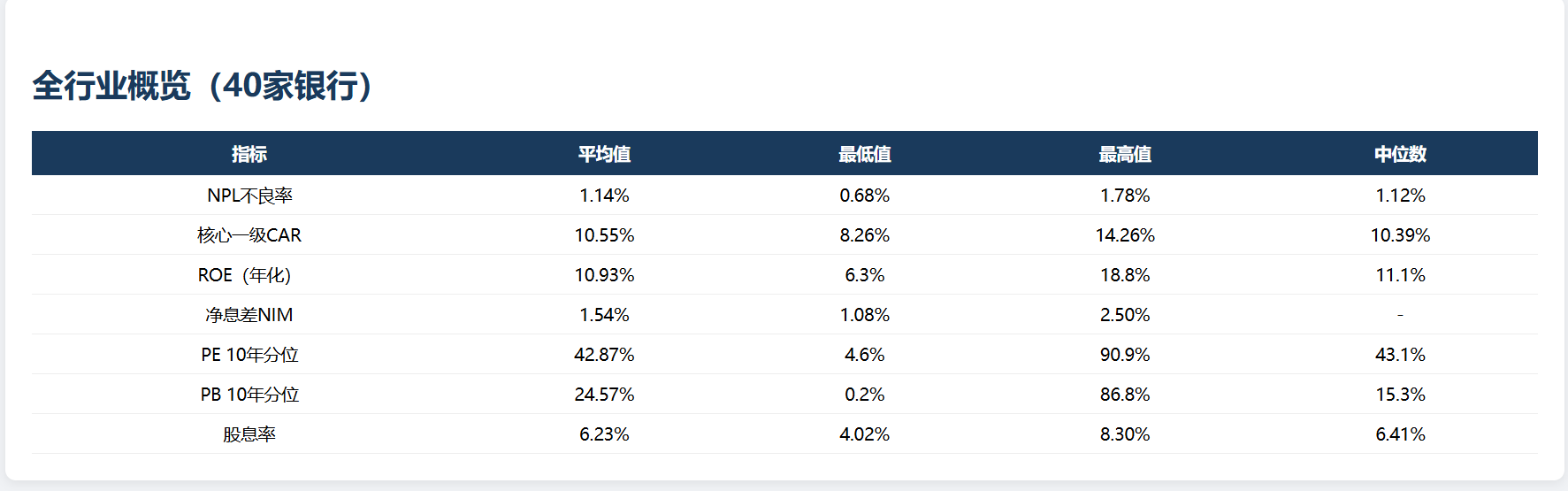
腾讯 WorkBuddy A 股投研案例拆解:40+ 标的横向对比、HTML 转 DOCX、知识库沉淀,为什么投研流程开始被 AI Agent 接管?
如果你把 WorkBuddy 在投研团队里的价值,只理解成“帮你写一篇研究报告”或者“顺手总结几份财报”,那基本还是看浅了。
我这次专门把腾讯云开发者社区那篇《用 WorkBuddy 搭建 A 股投研自动化流水线(实战教程)》重新拆了一遍。看完以后,我的判断很明确:
WorkBuddy 在 A 股投研这条线上最值得看的,不是会不会写结论,而是它已经开始把一整条研究流水线串起来:数据收集、横向比较、深研报告生成、格式转换、知识库沉淀。
这里先说一个边界,避免误读:
我不是在说所有投研团队都已经用同样的 WorkBuddy 前台界面跑这套流程。
更准确的说法是:
公开案例已经把 WorkBuddy 所在的腾讯 AI / Agent 工作流能力,放进了一个非常像真实投研生产环境的任务里。
先说结论
-
截至 2026 年 6 月 29 日,公开资料里,
WorkBuddy在 A 股投研最有说服力的,不是“写研报”这一个动作,而是四段连起来的流水线:- 数据收集与初步研究
- 生成 HTML 深研报告
- HTML 转 DOCX
- 上传知识库
-
公开稿件里最像真实生产环境的信号包括:
3个月真实使用经验40+标的横向对比- 知识库
4步上传链路 - 跨会话记忆管理
- HTML 转 DOCX 中文乱码、Token 过期、连接器断开 这些实战踩坑
-
如果你现在做的是:
- A 股研究
- 买方 / 卖方研究助理
- 行业跟踪
- 深研报告模板化
- 研究资料知识库沉淀
那这条线的参考价值,会比一般“AI 帮你写报告”的文章高很多。
为什么投研团队最容易被“流水线型 AI”打动
投研真正费时间的,通常不是写一句观点,而是:
- 先收数据
- 再看财报和研报
- 再做横向对比
- 再按固定结构写深研
- 最后还得把结果存档,方便下次继续研究
也就是说,这条线最烦人的通常不是结论本身,而是:
研究动作太碎,格式太多,成果又很难自然沉淀成长期资产。
这也是为什么我觉得,投研团队最需要的不是“更会说”的模型,而是:
- 能不能把研究流程拆成可重复步骤
- 能不能把格式转换做稳
- 能不能让研究记忆和知识库慢慢长出来
场景 1:A 股投研自动化的关键,不是“会分析”,而是能把分析接到交付
这篇公开稿最重要的一点,是它没有停在“AI 会不会给你一个研究结论”,而是直接把任务拆成了四段:
- 数据收集与初步研究
- 生成 HTML 深研报告
- HTML 转 DOCX
- 上传知识库
这其实非常真实。
因为很多投研团队今天最痛的,并不是“没结论”,而是:
- 结论散在不同会话里
- 过程没法复用
- 研究成果最后不容易沉淀进团队知识资产
而公开稿给出的这条链,本质上就在解决这个问题。
场景 2:40+ 标的横向对比,说明这不是单篇写作,而是批量研究工作
公开稿里最值得一提的细节之一,是:
40+标的横向对比
这为什么重要?
因为它说明这个案例不是“单独深挖一家公司”,而是在碰:
- 大量标的横向比较
- 行业结构化研究
- 模板化输出
这对 A 股研究来说特别关键,因为真正耗人的很多时候不是写一篇深研,而是:
- 先做一轮广撒网
- 再从里面筛值得深挖的标的
也就是说,WorkBuddy 在这里最有价值的地方,不一定是“写得像不像首席分析师”,而是:
它开始帮你接住前面那段高重复度、高格式依赖的基础研究工作。
场景 3:HTML 转 DOCX,看起来很小,实际上最像生产环境
很多人会忽略这条公开案例里最值钱的一个点:
- HTML 转 DOCX
但我反而觉得,这一段特别像真实工作。
因为很多所谓投研自动化,最后都停在:
- 聊天框里有一版结论
- Markdown 里有一版输出
- 但正式对外、对内流转还是要 Word / DOCX
只要最后这一步靠人工硬转,整条链路就断掉了。
所以这篇公开稿里提到的:
- HTML 转 DOCX
- 中文乱码问题
- Token 过期
- 连接器断开
反而让我更愿意相信这是一条真实跑过的生产路径,因为它连最烦人的交付边角料都踩到了。
这意味着 WorkBuddy 在这个场景里,不只是“帮你生成内容”,而是已经碰到:
研究产物真正要交付出去的最后一公里。
场景 4:知识库 4 步上传链路,说明目标不是一次性报告,而是研究资产沉淀
第二个我特别看重的信号是:
- 知识库
4步上传链路
这说明公开稿件的目标并不是做完一篇报告就结束,而是:
- 把研究过程和结果继续沉淀进知识库
- 让后续研究能复用前面的发现
- 让跨会话记忆真正接上
这点为什么重要?
因为很多投研团队真正缺的不是多一篇报告,而是:
让过去做过的研究不要每次都重来一遍。
如果研究成果不能沉淀,那 AI 最终只是一个一次性写作工具。 但如果研究成果能继续回流到知识库里,那它才更像:
一个逐渐长出团队研究资产的工作台。
场景 5:跨会话记忆管理,才是“跟踪式研究”能不能成立的关键
公开稿件还点到了:
- 跨会话记忆管理
这个点很值钱,因为 A 股研究从来都不是“一次性任务”。
真实环境里的节奏更像:
- 今天先看行业
- 明天补财报
- 下周更新估值
- 再下一轮叠加新公告、新政策、新业绩预告
如果 AI 每次都从零开始,它的价值就会被大幅打折。
而跨会话记忆管理真正有用的地方,就是让它开始具备一点:
连续跟踪同一批标的 / 同一条行业线索的能力。
场景 6:这条线为什么更像 WorkBuddy,而不是普通聊天模型
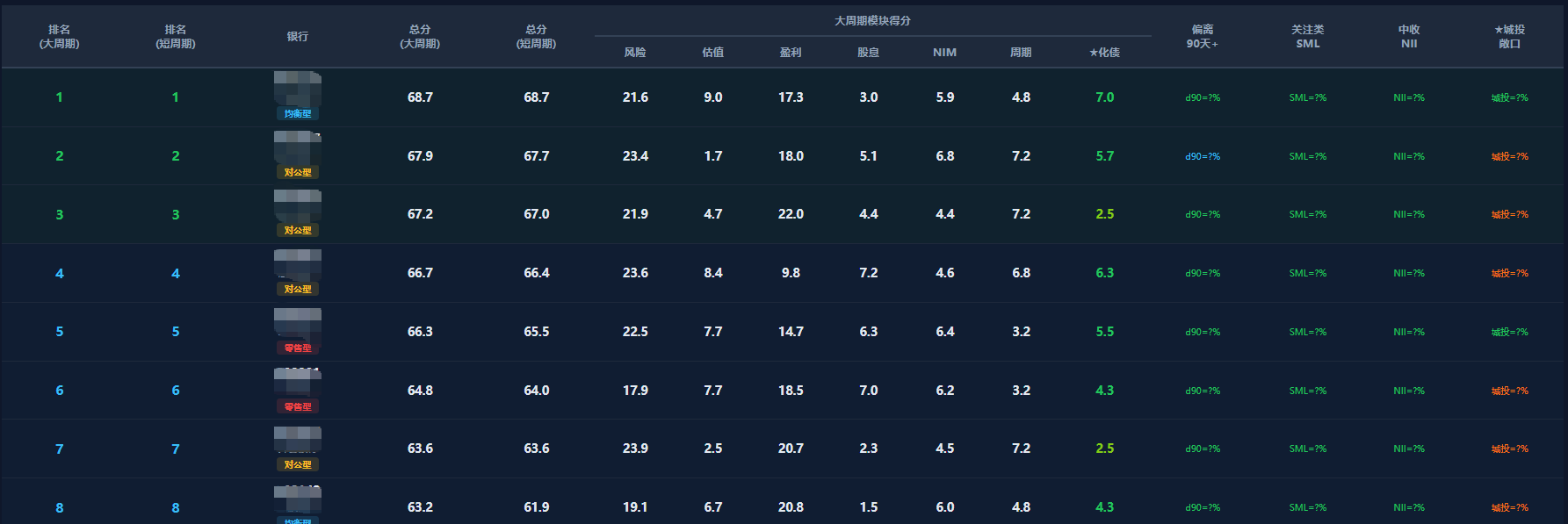
从公开案例看,WorkBuddy 在 A 股投研这条线上最像样的地方,不是“模型多强”,而是:
- 它能接住文件和资料
- 它能跨格式输出
- 它能把成果继续送进知识库
- 它能在多次会话之间维持研究上下文
这和普通聊天模型的区别非常明显。
普通模型更像:
- 你问一个问题
- 它给一个答案
而 WorkBuddy 在这个案例里的目标更像:
- 你启动一条研究链
- 它帮你把研究、生成、转换、沉淀这些步骤串起来
也就是说,它更像:
投研工作台
而不是:
一个会回答投资问题的聊天框。
哪些团队最适合先看这条线
适合马上研究的团队
- 做 A 股跟踪、行业研究、深研输出的团队
- 需要大量横向比较、模板化报告的研究岗
- 想把研究成果沉淀进知识库的团队
- 频繁要把研究内容转成正式文档交付的团队
可以先观望的团队
- 只做很轻量的一次性问答
- 没有固定的报告模板和知识沉淀需求
- 不需要跨会话追踪研究上下文
如果你想自己搭类似流程,我建议先看什么
如果你更关心的是:如何把数据收集、研究写作、格式转换和知识库沉淀接进自己的研究业务,可以先看:
比起只记住一个上游产品名,更重要的是先把:
- 模型能力
- 研究工作流
- 格式转换
- 知识沉淀链路
放在一个统一视角里看。
我的最终看法
如果只用一句话总结这篇 WorkBuddy A 股投研案例拆解,我的判断是:
它最值得重视的,不是“AI 也能写研报”,而是它已经开始进入投研团队真正费人的那条流水线:研究、生成、格式转换、知识库沉淀。
一旦这条链跑顺,WorkBuddy 看到的就不只是投研提效,而是:
研究资产怎样从一次性交付,变成可持续复用的团队知识系统。