腾讯 WorkBuddy 医疗行业案例拆解:医学数据分析、电子病历处理、百万级数据库校验为什么开始交给 AI Agent 了?
如果你把 WorkBuddy 在医疗行业里的价值,理解成“帮医生写点总结”或者“又一个能聊天的 AI 工具”,那基本上就看偏了。
我这次专门翻了几篇跟 医学数据分析、电子病历(EMR)、体检报告、医保流水、百万级数据库探查与质量校验 直接相关的公开稿件。看完以后,我的判断很明确:
WorkBuddy 在医疗行业最有价值的,不是把几句话写得更漂亮,而是它开始进入真正的医疗数据工作流。
而医疗数据团队最重的,往往不是“不会分析”,而是:
- 数据源太多
- 表太多
- 结构太乱
- 清洗和校验太耗时
- 标准化输出要一遍遍重来
这也是为什么我觉得,医疗行业反而是 WorkBuddy 这类 AI Agent 最容易先跑出真实价值的地方之一。
先说结论
- 截至 2026 年 6 月 29 日,公开资料里,
WorkBuddy在医疗行业最有说服力的落地,集中在三条线:- 医学数据清洗、字段探查与质量校验
- EMR、体检报告、医保流水等异构材料的结构化处理
- 多表关联、患者画像与标准化统计报告生成
- 从腾讯云开发者社区公开口径看,这些案例已经不是“拿 AI 试着玩玩”,而是出现了比较明确的:
- 数据规模
- 数据类型
- 多表结构
- 质量报告输出
- Skill 固化复用
- 以及较清楚的效率数字
- 如果你现在做的是医院信息科、医学数据分析、临床试验数据、BI、医保或医药数据处理,这条线的参考价值会比普通 AI 办公演示高很多。
为什么医疗行业最容易被“流程型 AI”打动
医疗团队真正累的,很多时候不是不会判断,而是:
- 表太多
- 字段太杂
- 资料来源太分散
- 数据结构不稳定
- 每周每月都要重复出报告
也就是说,医疗行业最烦人的通常不是“结论不会写”,而是:
从原始数据进来,到字段探查,到异常标记,到统计输出,到质量校验,这条链实在太长了。
而 WorkBuddy 在公开案例里最明显的特点,就是它不是一个孤立的聊天框,而是在往下面这些环节里走:
- 数据下载
- 数据清洗
- 字段探查
- 多表关联
- Word / Excel 输出
- 规则复用
- Skill 固化
这就让它看起来更像:
一个医疗数据自动化中枢
而不是:
一个帮你润色结论的模型窗口
案例 1:数百万条医疗数据,不是“查一查”这么简单
第一篇最像真实医疗生产环境的公开稿,是腾讯云开发者社区这篇:
《WorkBuddy 使用心得:一个医疗数据工作者的 AI 效率革命》
这篇最有价值的地方,在于它把医疗数据分析师的日常写得非常具体,而不是泛泛而谈。
公开稿件里直接点明,作者日常处理的是:
- 数百万条医疗数据
- 门诊处方
- 住院医嘱
- 药品出库记录
- 动辄几百张表、上百万条记录
这已经非常接近真实生产环境了。因为它不是拿一个小样本表格来演示,而是在说:
SQL 写到眼花,Python 脚本调到头秃,字段探查和清洗就要吃掉大把时间。
而 WorkBuddy 在这篇稿子里最关键的价值,不是“帮忙解释一下表字段”,而是接过了这些重复工作:
- 探查字段逻辑
- 标记异常值
- 生成 Excel 汇总表
- 生成 Word 格式数据质量校验报告
公开稿件里还给了比较清晰的效率口径:
- 单表数据探查从 2 到 3 小时 压到 15 分钟
- 多表关联分析从 1 到 2 天 压到 1 到 2 小时
- 两版数据对比从 3 到 4 小时 压到 10 分钟
- 部分步骤节省可到 95%
这类场景为什么真实?因为医疗数据团队最重的根本不是“有没有 AI 会写总结”,而是:
同一份输出背后,要反复做清洗、比对、汇总、校验这些没什么创意但很耗命的事。
案例 2:医疗数据里最值钱的,不是会不会 SQL,而是能不能把流程固化
同一篇公开稿里,另一个特别值得写进 SEO 稿的点,是它明确提到了 Skill。
作者把一整套流程固化成了可复用能力:
- 医疗数据库下载
- 清洗
- 生成汇总表
- 生成校验报告
以后每次拿到新数据,只要一句:
- “按医疗数据流程处理”
它就能自动走完整套步骤。
我觉得这个点特别重要,因为在医疗行业,真正折磨人的不是做一次,而是:
同样的流程每周、每月、每个项目都要再来一遍。
如果 WorkBuddy 真能把这些动作固化成 Skill,它的意义就不只是“节省时间”,而是:
开始把分析师脑子里的隐性流程,慢慢变成可重复跑的标准化工作流。
案例 3:240 万条记录、9 张表,这才像真正的数据库探查任务
第二篇特别值得放进医疗专题的公开文章,是:
《WorkBuddy 实战教程:从零完成百万级医疗数据库探查与质量校验》
这篇的价值很高,因为它给出了非常具体的任务规模:
- 9 张表
- 约 240 万条模拟医疗记录
- 涵盖:
- 门诊处方
- 住院医嘱
- 药品出库
- 费用明细
而且公开稿件把任务拆得非常像真实项目:
- 逐表探查字段逻辑,标记异常值和缺失项
- 按药品维度汇总出库数据
- 生成标准化数据质量校验报告
- 用多种方法交叉验证结果
这就不是“查一张表”的轻任务了,而是很标准的医疗数据库工作。
公开稿件里的效率对比也很抓人:
- 数据下载约 30 分钟 压到 5 分钟
- 字段探查从 3 到 4 小时 压到 15 分钟
- 质量报告从 2 到 3 小时 压到 5 分钟
- 多方法验证从 3 到 4 小时 压到 10 分钟
- 整体从 约 2 天 压到 约 45 分钟
- 效率提升约 95%
这类口径为什么有参考价值?因为它解决的是医疗数据工作里最麻烦的部分:
不是拿到数据,而是拿到数据以后怎么快速确认它到底能不能用。
案例 4:EMR、体检报告、医保流水,不是一个格式一个脚本就能搞定
第三篇特别适合补充医疗数据复杂度的公开文章,是:
《我用一只“龙虾”解放双手:WorkBuddy 深度赋能医学数据分析实战心得》
这篇的价值,在于它把医疗数据的“异构性”写得更清楚了。
公开稿件里直接点明,作者日常处理的是:
- 临床试验数据
- 电子病历(EMR)
- 体检报告
- 医保流水
这和前面两篇“数据库探查”非常互补。因为真实医疗生产环境里,麻烦的往往不是只有数据库,而是:
- 有的是结构化表
- 有的是 PDF / Word
- 有的是半结构化文本
- 还有跨来源的字段命名和规则不统一
公开稿件里提到几个特别像真实生产环境的动作:
- 上传样本 PDF,直接做文档理解
- 识别指标高低符号,并给出简短临床意义短评
- 将门诊 Excel 诊断列表与住院部用药清单做关联
- 基于患者 ID 左连接多张表
- 生成简单的“患者画像”和合并症字段
这意味着 WorkBuddy 在这个案例里已经不是只会“读表”,而是在碰:
- OCR / 文档理解
- 医学规则复用
- 表格关联
- 结构化输出
这对医疗数据团队很关键,因为很多工作的真正难点,不在于写 SQL,而在于:
不同数据源到底怎么拼到一起。
案例 5:标准化统计报告,才是很多医学数据团队最重复的重活
同一篇公开稿里,还有一个我觉得特别值得放进文章里的点:
- 《临床试验受试者安全性数据周报》自动生成
这类场景在医疗行业非常常见。因为每周、每月、每项目都要出:
- 安全性周报
- 异常事件统计
- 对比结论
- 指标趋势说明
公开稿件里提到的做法是:
- 给
WorkBuddy设定固定角色 - 指定固定输出格式
- 让它自动总结每周新增不良事件与对比变化
我觉得这个点很值钱,因为它说明 WorkBuddy 在医疗行业里并不是只处理原始数据,而是已经开始往:
- 数据处理
- 统计输出
- 文字报告
这一整条交付链路上走。
从公开资料看,医疗平台这条线本来就强调“平台化”和“档案化”
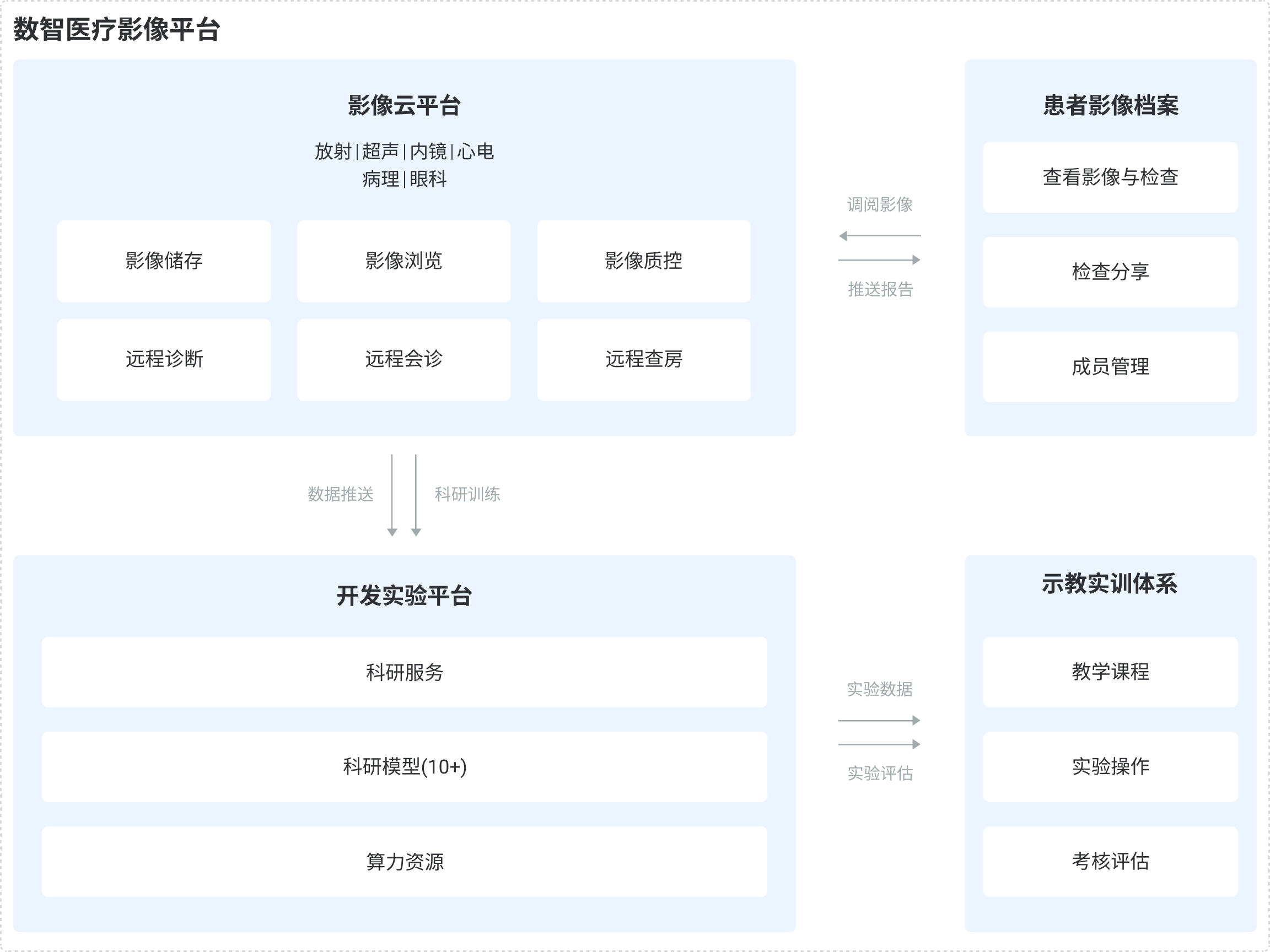
如果说前面三篇公开稿更偏个人或团队的一线实战,那腾讯医疗公开资料也给了一个更宏观的信号:
- 医疗数据和医疗影像这条线,本来就是平台化、档案化、协同化的场景。
从公开图里能直接看到:
- 影像云平台
- 患者影像档案
- 远程诊断
- 远程会诊
- 检查分享
- 成员管理
这虽然不是 WorkBuddy 本身的截图,但它能帮助我们理解一件事:
医疗行业对“平台 + 数据 + 规则 + 协同”的需求本来就特别强。
而 WorkBuddy 这种擅长把数据处理、规则复用、报告输出串起来的 Agent,正好容易嵌进这类环境里。
从这些公开案例里,我看到的医疗生产环境长什么样
把上面几篇公开稿拼起来看,WorkBuddy 在医疗行业里的生产环境,已经出现了这些共性:
- 有真实数据规模,不是演示样本
- 数百万条数据
- 240 万条记录
- 9 张表
- 有真实数据类型,不是单一表格
- 门诊处方
- 住院医嘱
- 药品出库
- 费用明细
- EMR
- 体检报告
- 医保流水
- 有真实输出要求,不只是回答问题
- Excel 汇总表
- Word 校验报告
- 患者画像
- 临床试验周报
- 有真实方法,不只是“帮我分析”
- 字段探查
- 异常标记
- 多表关联
- 多方法交叉验证
- Skill 固化
这也是为什么我觉得它在医疗行业里更像:
医学数据自动化工作台
而不是:
一个普通聊天 AI
它现在最适合哪些医疗团队先试
适合马上试的人
- 医院信息科和医学数据分析团队
- 需要清洗 EMR、体检报告、医保流水的团队
- 临床试验、药物安全、周报月报高频输出团队
- 需要做多表关联、患者画像、字段校验的 BI 团队
- 已经有固定流程,想把它们固化成 Skill 的组织
可以先观望的人
- 没有稳定高频流程、任务完全一次性的团队
- 暂时不愿意梳理规则和标准输出格式的团队
- 只想做简单问答,不打算把 AI 接进数据工作流的人
如果你想自己测,我建议这样测
- 先挑一个最标准、最高频的医疗数据流程,不要一上来就想“全院改造”。
- 医疗场景里最适合先试的切口通常是:
- 字段探查和异常标记
- 数据质量校验报告
- EMR / 体检报告结构化
- 周报月报自动生成
- 不只看“能不能跑出来”,重点看:
- 规则是否稳定
- 报告格式是否可复用
- 多表关联是否准确
- 关键结果是否支持抽检和交叉验证
- 如果你们本来就在做多系统协同,也可以顺手比较:
- 哪些场景适合
WorkBuddy这种工作台式 Agent - 哪些场景更适合继续自己走 API 或数据平台编排
- 哪些场景适合
如果你现在更关心的是:怎样把腾讯系、GLM、Kimi、DeepSeek、StepFun 等模型统一接进自己的 Agent 工作流,可以先看:
我的最终判断
如果一句话总结我对 WorkBuddy 医疗行业案例 的看法,那就是:
它最值得重视的,不是“AI 能不能帮医疗团队省一点时间”,而是它已经开始进入医学数据清洗、EMR 处理、百万级数据库探查、数据质量校验和标准化报告这些真正高频、重复、容易把人耗空的链路。
这比“会不会写一段医疗总结”重要得多。因为医疗数据工作最难的,从来都不是一句结论,而是:
把一堆异构、反复、标准严格、还要交叉验证的数据流程,稳定地跑顺。
如果 WorkBuddy 真在这些地方跑起来了,它对医疗行业的意义就不是“提一点效率”,而是:
开始把原本靠大量人工反复搬运和校验的分析链路,慢慢收编进一个可重复、可复用、可持续的 AI 工作台里。